Appearance
Webpack 默认会将尽可能多的模块代码打包在一起,优点是能减少最终页面的 HTTP 请求数,但缺点也很明显:
- 页面初始代码包过大,影响首屏渲染性能;
- 无法有效应用浏览器缓存,特别对于 NPM 包这类变动较少的代码,业务代码哪怕改了一行都会导致 NPM 包缓存失效。
为此,Webpack 提供了 SplitChunksPlugin 插件,专门用于根据产物包的体积、引用次数等做分包优化,规避上述问题,特别适合生产环境使用。
不过,SplitChunksPlugin 的使用方法比较复杂,我们得从 Chunk 这个概念开始说起。
深入理解Chunk
Chunk 是 Webpack 内部一个非常重要的底层设计,用于组织、管理、优化最终产物,在构建流程进入生成(Seal)阶段后:
- Webpack 首先根据
entry配置创建若干 Chunk 对象; - 遍历构建(Make)阶段找到的所有 Module 对象,同一 Entry 下的模块分配到 Entry 对应的 Chunk 中;
- 遇到异步模块则创建新的 Chunk 对象,并将异步模块放入该 Chunk;
- 分配完毕后,根据 SplitChunksPlugin 的启发式算法进一步对这些 Chunk 执行裁剪、拆分、合并、代码调优,最终调整成运行性能(可能)更优的形态;
- 最后,将这些 Chunk 一个个输出成最终的产物(Asset)文件,编译工作到此结束。
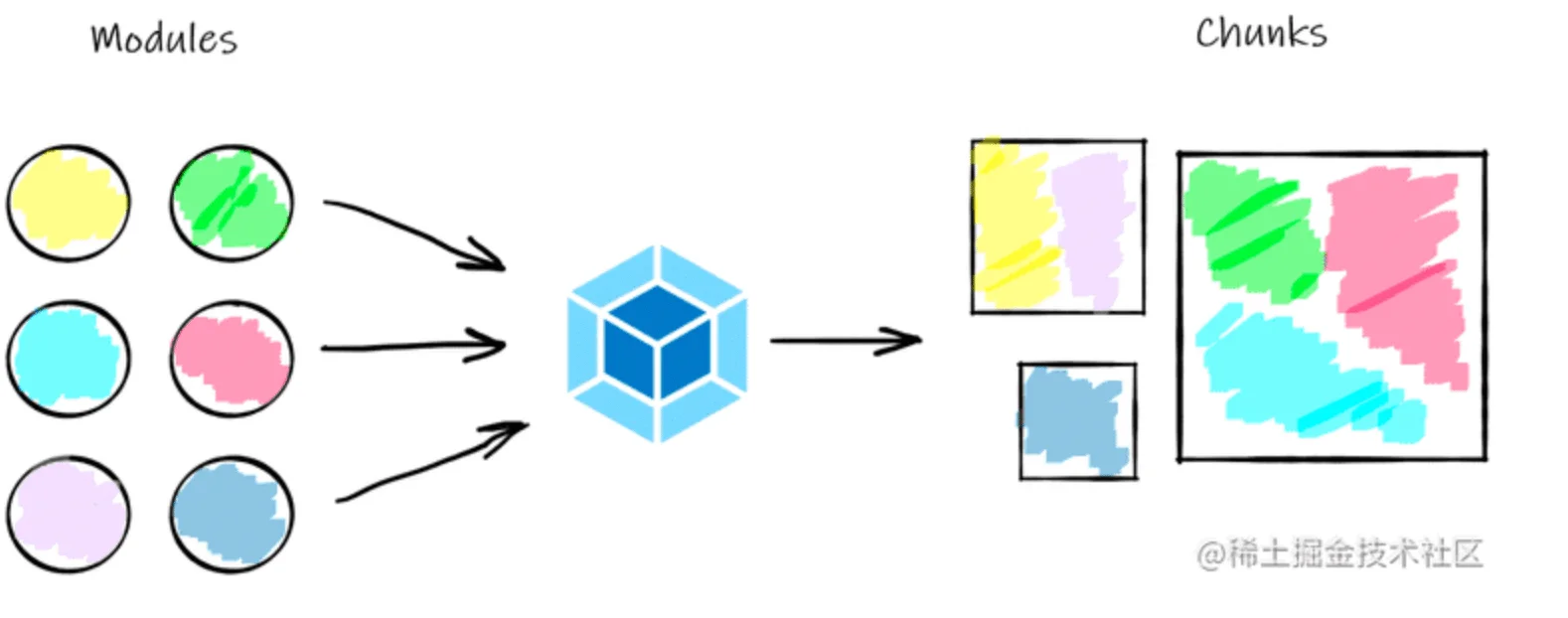
📚可以看出,Chunk 在构建流程中起着承上启下的关键作用:
- 一方面作为 Module 容器,根据一系列默认 分包策略 决定哪些模块应该合并在一起打包;
- 另一方面根据
splitChunks设定的 策略 优化分包,决定最终输出多少产物文件。
Chunk 分包结果的好坏直接影响了最终应用性能,Webpack 默认会将以下三种模块做分包处理:
Initial Chunk:entry模块及相应子模块打包成 Initial Chunk;Async Chunk:通过import('./xx')等语句导入的异步模块及相应子模块组成的 Async Chunk;Runtime Chunk:运行时代码抽离成 Runtime Chunk,可通过 entry.runtime 配置项实现。
Runtime Chunk 规则比较简单,本文先不关注,但 Initial Chunk 与 Async Chunk 这种略显粗暴的规则会带来两个明显问题
模块重复打包
假如多个 Chunk 同时依赖同一个 Module,那么这个 Module 会被不受限制地重复打包进这些 Chunk,例如对于下面的模块关系:
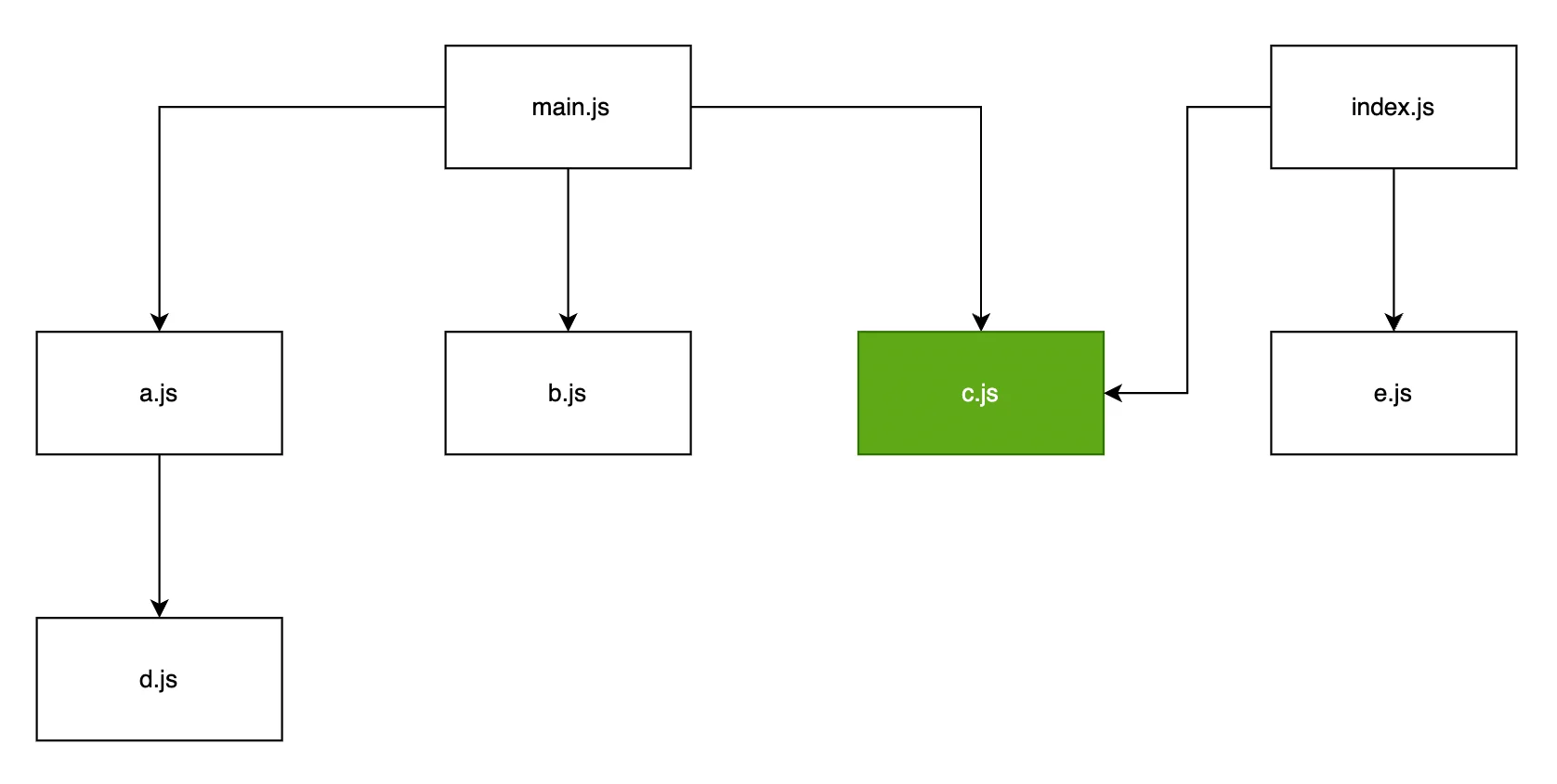
示例中 main/index 入口(entry)同时依赖于 c 模块,默认情况下 Webpack 不会对此做任何优化处理,只是单纯地将 c 模块同时打包进 main/index 两个 Chunk😅:
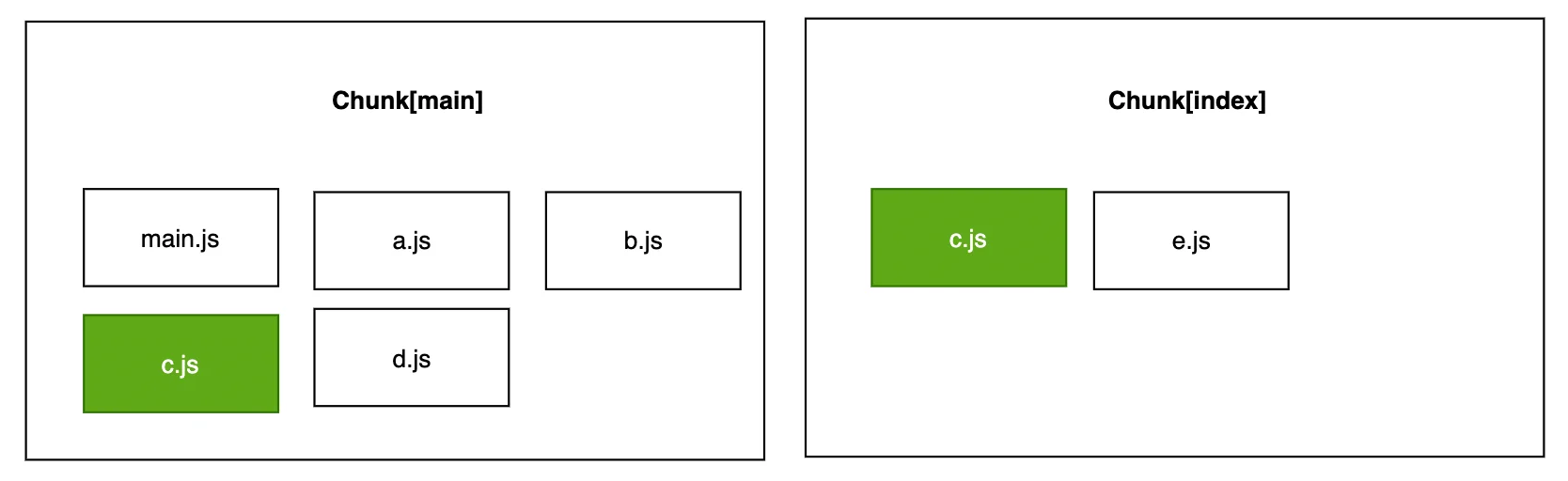
资源冗余 & 低效缓存
Webpack 会将 Entry 模块、异步模块所有代码都打进同一个单独的包,这在小型项目通常不会有明显的性能问题,但伴随着项目的推进,包体积逐步增长可能会导致应用的响应耗时越来越长。归根结底这种将所有资源打包成一个文件的方式存在两个弊端:
- 资源冗余:客户端必须等待整个应用的代码包都加载完毕才能启动运行,但可能用户当下访问的内容只需要使用其中一部分代码
- 缓存失效:将所有资源打成一个包后,所有改动 —— 即使只是修改了一个字符,客户端都需要重新下载整个代码包,缓存命中率极低
这两个问题都可以通过更科学的分包策略解决,例如:
- 将被多个 Chunk 依赖的包分离成独立 Chunk,防止资源重复;
node_modules中的资源通常变动较少,可以抽成一个独立的包,业务代码的频繁变动不会导致这部分第三方库资源缓存失效,被无意义地重复加载。
为此,Webpack 专门提供了 SplitChunksPlugin 插件,用于实现更灵活、可配置的分包,提升应用性能。
SplitChunksPlugin简介
SplitChunksPlugin是 Webpack 4 之后内置实现的最新分包方案,与 Webpack3 时代的 CommonsChunkPlugin 相比,它能够基于一些更灵活、合理的启发式规则将 Module 编排进不同的 Chunk,最终构建出性能更佳,缓存更友好的应用产物。
SplitChunksPlugin 的用法比较抽象,算得上 Webpack 的一个难点,主要能力有:
SplitChunksPlugin支持根据 Module 路径、Module 被引用次数、Chunk 大小、Chunk 请求数等决定是否对 Chunk 做进一步拆解,这些决策都可以通过optimization.splitChunks相应配置项调整定制,基于这些能力我们可以实现:- 单独打包某些特定路径的内容,例如
node_modules打包为vendors; - 单独打包使用频率较高的文件;
- 单独打包某些特定路径的内容,例如
SplitChunksPlugin还提供了optimization.splitChunks.cacheGroup概念,用于对不同特点的资源做分组处理,并为这些分组设置更有针对性的分包规则;SplitChunksPlugin还内置了default与defaultVendors两个cacheGroup,提供一些开箱即用的分包特性:node_modules资源会命中defaultVendors规则,并被单独打包;- 只有包体超过 30kb 的 Chunk 才会被单独打包;
- 加载 Async Chunk 所需请求数不得超过 30;
- 加载 Initial Chunk 所需请求数不得超过 30。
WARNING
这里所说的请求数不能等价对标到 http 资源请求数,下面会细讲。
由于 Webpack4 开始已经内置支持 SplitChunksPlugin ,我们不需要额外安装依赖,直接修改 optimization.splitChunks 配置项即可实现自定义的分包策略:
js
module.exports = {
//...
optimization: {
splitChunks: {
// ...
},
},
}splitChunks 主要有两种类型的配置:
minChunks/minSize/maxInitialRequest等分包条件,满足这些条件的模块都会被执行分包;cacheGroup:用于为特定资源声明特定分包条件,例如可以为node_modules包设定更宽松的分包条件。
Claude关于minSize/minChunks/maxInitialRequest解释
minSize、maxSize 和 minChunks 都是 SplitChunksPlugin 中很重要的拆分规则配置。它们的用法如下:
minSize: 提取的 chunk 最小大小,默认为 30000(30kb)。
- 作用: 防止提取出来的 chunk 体积太小,导致 HTTP 请求数量过多。
- 配置建议: 根据项目的体积扩容阈值设置一个合理的值。一般不小于 30kb。
maxSize: 提取的 chunk 最大大小,默认为 0,表示无限制。
- 作用: 防止提取出的单一 chunk 体积过大,体验不佳。
- 配置建议: 可以设置为 600kb 到 1000kb 之间的一个值。具体根据项目情况配置。
minChunks: 模块至少在 minChunks 中重复出现,才会被提取到缓存组。默认为 1。
- 作用: 控制被提取模块的重复率,避免 appeared-once 现象。
- 配置建议: 一般设置为 2 或 3。不能设置过大,否则公共模块提取不出来,失去优化意义。
这三个规则的关系可以描述为:Extractor = minSize <= chunkSize <= maxSize && occurrences >= minChunks也就是当模块体积在 minSize 和 maxSize 范围内,且其出现次数不小于 minChunks 时,才会被 SplitChunksPlugin 提取到缓存组中。
通过均衡地配置这三个值,可以实现:
- 避免请求过多导致的性能损耗;
- 提取出合理体积的 chunk,既不会文件过小导致的请求浪费,也不会文件过大导致的加载慢;
- 选择出现频率高的模块进行提取,获得最大的优化效果。这三个规则的灵活运用,是使用 SplitChunksPlugin 优化代码的关键。理解每个规则的作用及其之间的关系,可以更好地配置出满足需求的拆分结果。
设置分包范围
首先,SplitChunksPlugin 默认情况下只对 Async Chunk 生效,我们可以通过 splitChunks.chunks 调整作用范围,该配置项支持如下值:
- 字符串
'all':对 Initial Chunk 与 Async Chunk 都生效,建议优先使用该值;✅ - 字符串
'initial':只对 Initial Chunk 生效; - 字符串
'async':只对 Async Chunk 生效; - 函数
(chunk) => boolean:该函数返回true时生效;
🌰
js
module.exports = {
// ...
optimization: {
splitChunks: {
chunks: 'all'
}
}
}设置为 all 效果最佳,此时 Initial Chunk、Async Chunk 都会被 SplitChunksPlugin 插件优化。
根据 Module 使用频率分包
SplitChunksPlugin 支持按 Module 被 Chunk 引用的次数决定是否分包,借助这种能力我们可以轻易将那些被频繁使用的
js
module.exports = {
// ...
optimization: {
// 设定引用次数超过 2 的模块才进行分包
minChunks: 2
}
}🚨注意,这里“被 Chunk 引用次数”并不直接等价于被 import 的次数,而是取决于上游调用者是否被视作 Initial Chunk 或 Async Chunk 处理,例如:
js
// common.js
export default "common chunk";
// async-module.js
import common from './common'
// entry-a.js
import common from './common'
import('./async-module')
// entry-b.js
import common from './common'上例包含四个模块,形成如下模块关系图:
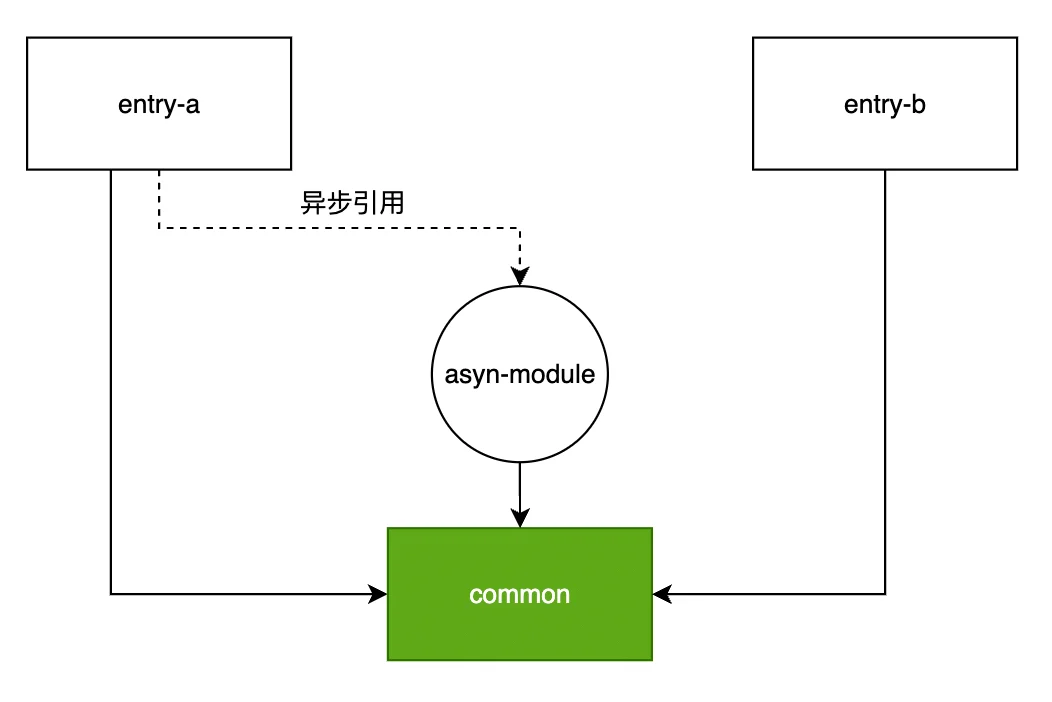
其中,entry-a、entry-b 分别被视作 Initial Chunk 处理;async-module 被 entry-a 以异步方式引入,因此被视作 Async Chunk 处理。那么对于 common 模块来说,分别被三个不同的 Chunk 引入,此时引用次数为 3,配合下面的配置:
js
module.exports = {
entry: {
entry1: './src/entry-a.js',
entry2: './src/entry-b.js'
},
// ...
optimization: {
splitChunks: {
minChunk: 2,
// ...
}
}
}common 模块命中 optimization.splitChunks.minChunks = 2 规则,因此该模块可能会被单独分包,最终产物:
entry1.jsentry1.jsasync-module.jscommon.js
WARNING
强调一下,上面说的是“可能”,minChunks 并不是唯一条件,此外还需要满足诸如 minSize、chunks 等限制条件才会真正执行分包,接着往下看。
限制分包数量
在 minChunks 基础上,为防止最终产物文件数量过多导致 HTTP 网络请求数剧增,反而降低应用性能,Webpack 还提供了 maxInitialRequest/maxAsyncRequest 配置项,用于限制分包数量:
maxInitialRequests:用于设置 Initial Chunk 最大并行请求数;maxAsyncRequests:用于设置 Async Chunk 最大并行请求数。
👩🏫敲重点,"请求数" 这个概念有点复杂:
这里所说的“请求数”,是指加载一个 Chunk 时所需要加载的所有分包数。例如对于一个 Chunk A,如果根据分包规则(如模块引用次数、第三方包)分离出了若干子 Chunk A[¡],那么加载 A 时,浏览器需要同时加载所有的 A[¡],此时并行请求数等于 ¡ 个分包加 A 主包,即 ¡+1。
INFO
通过 emitAssets 等方式直接输出产物文件不在此范畴。
1️⃣ 举个例子,对于上例所说的模块关系:
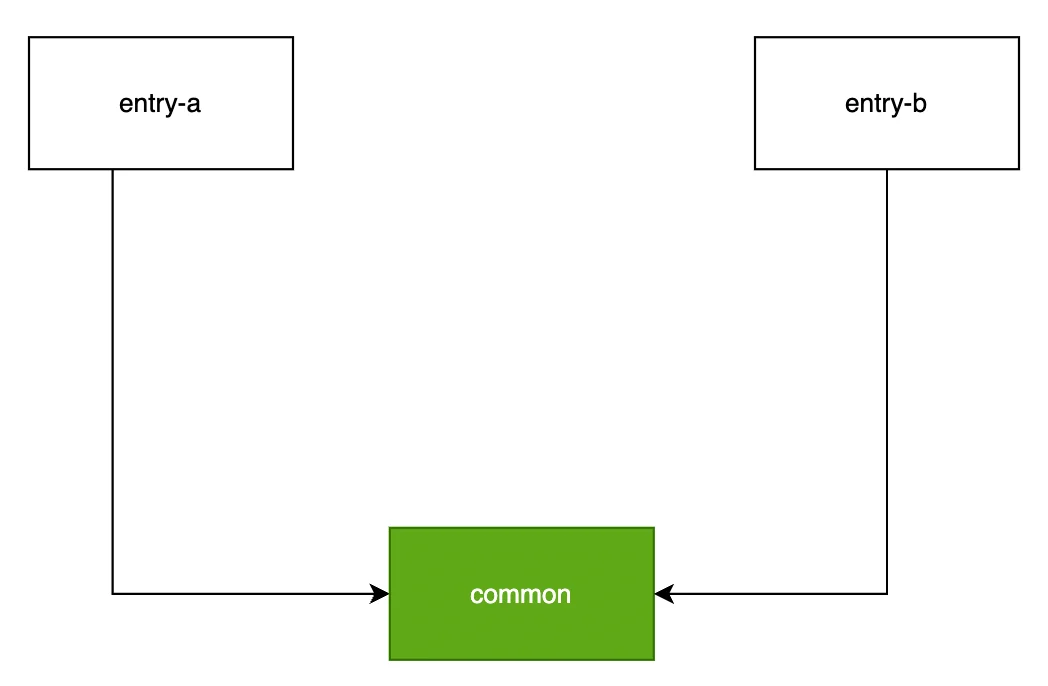
若 minChunks = 2 ,则 common 模块命中 minChunks 规则被独立分包,浏览器请求 entry-a 时,则需要同时请求 common 包,并行请求数为 1 + 1=2。
2️⃣而对于下述模块关系:
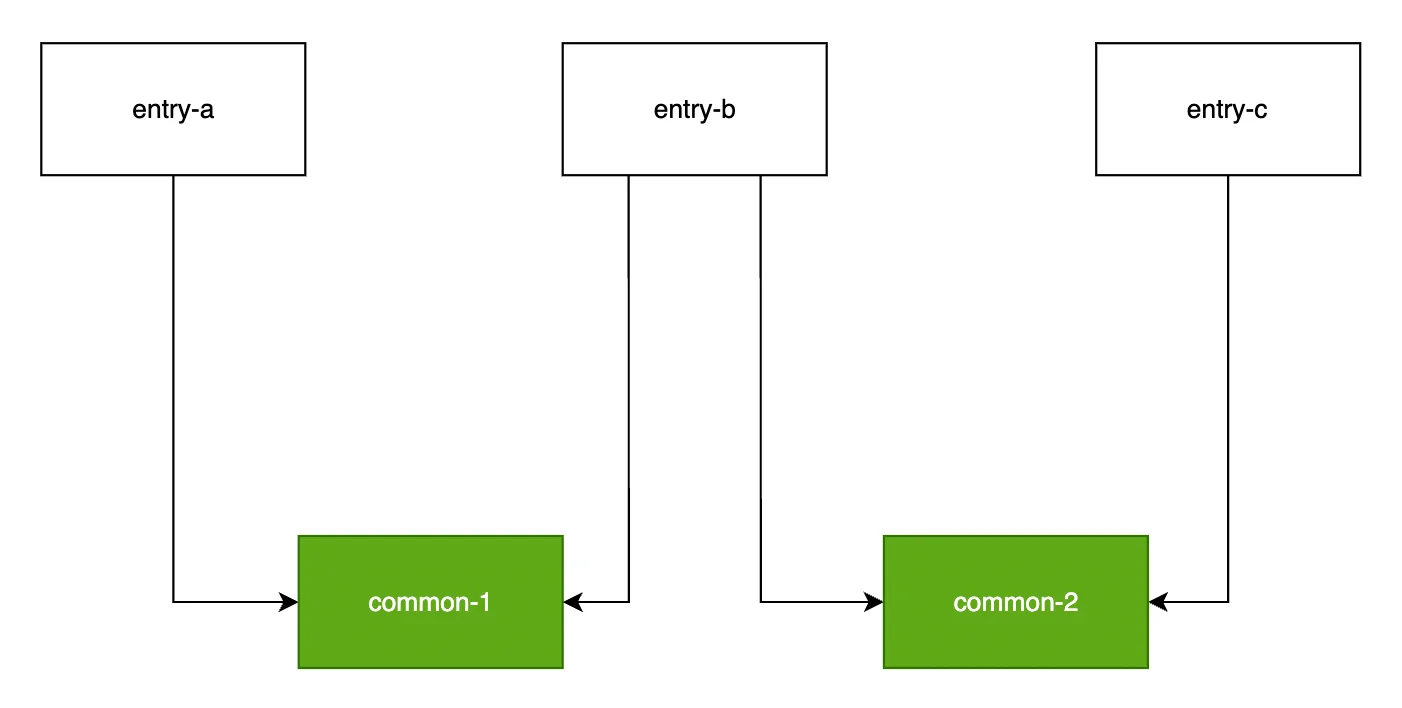
若 minChunks = 2 ,则 common-1 、common-2 同时命中 minChunks 规则被分别打包,浏览器请求 entry-b 时需要同时请求 common-1 、common-2 两个分包,并行数为 2 + 1 = 3,此时若 maxInitialRequest = 2,则分包数超过阈值,SplitChunksPlugin 会 放弃 common-1、common-2 中体积较小的分包。maxAsyncRequests 逻辑与此类似,不在赘述。
并行请求数关键逻辑总结如下:
- Initial Chunk 本身算一个请求;
- Async Chunk 不算并行请求;
- 通过
runtimeChunk拆分出的 runtime 不算并行请求; - 如果同时有两个 Chunk 满足拆分规则,但是
maxInitialRequests(或maxAsyncRequests) 的值只能允许再拆分一个模块,那么体积更大的模块会被优先拆解。😎
限制分包体积
除上面介绍的 minChunks —— 模块被引用次数,以及 maxXXXRequests —— 包数量,这两个条件外,Webpack 还提供了一系列与 Chunk 大小有关的分包判定规则,借助这些规则我们可以实现当包体过小时直接取消分包 —— 防止产物过"碎";当包体过大时尝试对 Chunk 再做拆解 —— 避免单个 Chunk 过大。
这一规则相关的配置项有:
minSize: 超过这个尺寸的 Chunk 才会正式被分包;maxSize: 超过这个尺寸的 Chunk 会尝试进一步拆分出更小的 Chunk;maxAsyncSize: 与maxSize功能类似,但只对异步引入的模块生效;maxInitialSize: 与maxSize类似,但只对entry配置的入口模块生效;enforceSizeThreshold: 超过这个尺寸的 Chunk 会被强制分包,忽略上述其它 Size 限制。
🎉那么,结合前面介绍的两种规则,SplitChunksPlugin 的主体流程如下:
SplitChunksPlugin尝试将命中minChunks规则的 Module 统一抽到一个额外的 Chunk 对象;- 判断该 Chunk 是否满足
maxInitialRequests阈值,若满足则进行下一步; - 判断该 Chunk 资源的体积是否大于上述配置项
minSize声明的下限阈值;- 如果体积小于
minSize则取消这次分包,对应的 Module 依然会被合并入原来的 Chunk - 如果 Chunk 体积大于
minSize则判断是否超过maxSize、maxAsyncSize、maxInitialSize声明的上限阈值,如果超过则尝试将该 Chunk 继续分割成更小的部分
- 如果体积小于
TIP
虽然 maxSize 等阈值规则会产生更多的包体,但缓存粒度会更小,命中率相对也会更高,配合持久缓存与 HTTP2 的多路复用能力,网络性能反而会有正向收益。
🌰以上述模块关系为例:
若此时 Webpack 配置的 minChunks 大于 2,且 maxInitialRequests 也同样大于 2,如果 common 模块的体积大于上述说明的 minSize 配置项则分包成功,common 会被分离为单独的 Chunk,否则会被合并入原来的 3 个 Chunk。
TIP
注意,这些条件的优先级顺序为: maxInitialRequest/maxAsyncRequests < maxSize < minSize。而命中 enforceSizeThreshold 阈值的 Chunk 会直接跳过这些条件判断,强制进行分包。
缓存组 cacheGroups 简介
上述 minChunks、maxInitialRequests、minSize 都属于分包条件,决定是否对什么情况下对那些 Module 做分包处理。此外, SplitChunksPlugin 还提供了 cacheGroups 配置项用于为不同文件组设置不同的规则,例如:
js
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
minChunks: 1,
minSize: 0
}
},
},
},
};示例通过 cacheGroups 属性设置 vendors 缓存组,所有命中 vendors.test 规则的模块都会被归类 vendors 分组,优先应用该组下的 minChunks、minSize 等分包配置。
cacheGroups 支持上述 minSize/minChunks/maxInitialRequests 等条件配置,此外还支持一些与分组逻辑强相关的属性,包括:
test:接受正则表达式、函数及字符串,所有符合test判断的 Module 或 Chunk 都会被分到该组;type:接受正则表达式、函数及字符串,与test类似均用于筛选分组命中的模块,区别是它判断的依据是文件类型而不是文件名,例如type = 'json'会命中所有 JSON 文件;idHint:字符串型,用于设置 Chunk ID,它还会被追加到最终产物文件名中,例如idHint = 'vendors'时,输出产物文件名形如vendors-xxx-xxx.js;priority:数字型,用于设置该分组的优先级,若模块命中多个缓存组,则优先被分到priority更大的组。
缓存组的作用在于能为不同类型的资源设置更具适用性的分包规则,一个典型场景是将所有 node_modules 下的模块统一打包到 vendors 产物,从而实现第三方库与业务代码的分离。
Webpack 提供了两个开箱即用的 cacheGroups,分别命名为 default 与 defaultVendors,默认配置:
js
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
default: {
idHint: "",
reuseExistingChunk: true,
minChunks: 2,
priority: -20
},
defaultVendors: {
idHint: "vendors",
reuseExistingChunk: true,
test: /[\\/]node_modules[\\/]/i,
priority: -10
}
},
},
},
};这两个配置组能帮助我们:
- 将所有
node_modules中的资源单独打包到vendors-xxx-xx.js命名的产物 - 对引用次数大于等于 2 的模块 —— 也就是被多个 Chunk 引用的模块,单独打包
开发者也可以将默认分组设置为 false,关闭分组配置,例如:
js
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
default: false
},
},
},
};配置项与最佳实践
最后,我们再回顾一下 SplitChunksPlugin 支持的配置项:
minChunks:用于设置引用阈值,被引用次数超过该阈值的 Module 才会进行分包处理;maxInitialRequests/maxAsyncRequests:用于限制 Initial Chunk(或 Async Chunk) 最大并行请求数,本质上是在限制最终产生的分包数量;minSize: 超过这个尺寸的 Chunk 才会正式被分包;maxSize: 超过这个尺寸的 Chunk 会尝试继续做分包;maxAsyncSize: 与maxSize功能类似,但只对异步引入的模块生效;maxInitialSize: 与maxSize类似,但只对entry配置的入口模块生效;enforceSizeThreshold: 超过这个尺寸的 Chunk 会被强制分包,忽略上述其它 size 限制;cacheGroups:用于设置缓存组规则,为不同类型的资源设置更有针对性的分包策略。
结合这些特性,业界已经总结了许多惯用的最佳分包策略,包括:
- 针对
node_modules资源:- 可以将
node_modules模块打包成单独文件(通过cacheGroups实现),防止业务代码的变更影响 NPM 包缓存,同时建议通过maxSize设定阈值,防止 vendor 包体过大; - 更激进的,如果生产环境已经部署 HTTP2/3 一类高性能网络协议,甚至可以考虑将每一个 NPM 包都打包成单独文件,具体实现可查看小册示例;
- 可以将
- 针对业务代码:
- 设置
common分组,通过minChunks配置项将使用率较高的资源合并为 Common 资源; - 首屏用不上的代码,尽量以异步方式引入;
- 设置
optimization.runtimeChunk为true,将运行时代码拆分为独立资源。
- 设置
不过,现实世界很复杂,同样的方法放在不同场景可能会有完全相反的效果,建议你根据自己项目的实际情况(代码量、基础设施环境),择优选用上述实践。
总结
Chunk 是 Webpack 实现模块打包的关键设计,Webpack 会首先为 Entry 模块、异步模块、Runtime 模块(取决于配置) 创建 Chunk 容器,之后按照 splitChunks 配置进一步优化、裁剪分包内容。
splitChunks 规则比较复杂,大致上可以分类为:
- 规则类:如
minSize/minChunks等,匹配这些条件的 Module 都会被单独分包; cacheGroup:可以理解为针对特定资源的次级规则集合。
实践中,分包策略的好坏直接影响应用的运行性能,常用策略一是单独打包 node_modules 代码(习惯称为 vendor),二是单独打包被频繁使用的模块(习惯称为 common)。
思考题
SplitChunksPlugin 的用法比较复杂,建议你尝试写一些 demo,组合各种形态的配置值,深入理解配置项背后的隐晦逻辑。
SplitChunksPlugin实现chunks拆分的原理
- 分析模块之间的依赖关系,找到可以被提取出来的模块。
- 根据配置的规则,决定这些模块应该放到哪个缓存组中。
- 根据缓存组的配置,将这些模块提取出来,形成一个单独的 chunk。
- 将原来的 chunks 中的模块替换为该 chunk 的引用。
- 在页面中加载这个新生成的 chunk。
具体的实现过程如下:
- 在编译阶段的优化钩子函数中,对所有模块及其依赖进行深度优先遍历。
- 根据 minSize、maxSize 和 minChunks 等规则过滤掉不符合条件的模块。
- 对符合条件的模块,根据 module 和 chunks 的名称、来源等属性决定它属于哪个缓存组。每个模块只能属于一个缓存组。
- 遍历所有的缓存组,根据每个组的设置,决定从哪些 chunk 中提取模块到该组中。
- 将选出的模块移动到该缓存组的 chunk 中。
- 更新原 chunks 中对这些模块的引用,指向新的 chunk。
- 为新生成的 chunk 配置加载规则,在页面加载时请求该 chunk。
- 最终页面上加载的不是许多小的重复 chunk,而是一些更大的共用 chunk。
所以,SplitChunksPlugin 的原理是通过分析模块关系,提取公共模块到更大的 chunk 中,减小重复模块的资源请求次数,提高缓存利用效率,优化页面加载性能。这是它实现代码拆分的核心原理。
扩展阅读:
- 🔥Webpack: An in-depth introduction to SplitChunksPlugin Webpack:SplitChunksPlugin - @indepth.dev 理解如何分包必读🚀
2023-04-14 11:48:41